RoCE or Infiniband? Which one is better for HPC nerwork
获取链接
Facebook
X
Pinterest
电子邮件
其他应用
What Is HPC (High-Performance Computing)
High-performance computing is the capability of processing data and performing complex calculations at extremely high speeds. For example, a laptop or desktop computer with a 3 GHz processor can perform about 3 billion calculations per second, which is much faster than any human being can achieves, but it still pales in comparison to HPC solutions that can perform trillions of calculations per second. The general architecture of HPC is mainly composed of computing, storage, and network. The reason why HPC can improve the computing speed is that it adopts “parallel technology”, using multiple computers to work together, using ten, hundreds, or even thousands of computers, which enables them “working in parallel”. Each computer needs to communicate with each other and process tasks cooperatively, which requires a high-speed network with strict requirements on latency and bandwidth.
Key Factors of HPC Performance
Processor performance: This refers to the central processing unit (CPU) or graphics processing unit (GPU)’s processing power. To increase processing power, HPC systems often use multiple processors working in tandem.
Memory performance: HPC systems require a large amount of memory (RAM) to support complex computations and large data sets. This factor refers to the speed and capacity of the system memory.
I/O Performance: The speed at which data is imported and exported from storage devices is critical to the performance of an HPC system. To support fast processing of large data sets, high-speed storage devices are necessary.
Network Performance: HPC systems rely on a high-speed network to connect their various components and support communication between multiple processors and storage devices. This factor refers to the speed and capacity of the network.
Application scenarios of High-performance computing (HPC)
High-performance computing (HPC) demands diverse network performance levels based on various application scenarios. These scenarios can be broadly categorized into three distinct types:
Loosely Coupled Computing Scenario: Here, computing nodes operate with minimal dependence on each other’s information, resulting in lower network performance requirements. Examples include financial risk assessment, remote sensing and mapping, and molecular dynamics. This scenario imposes relatively low demands on the network.
Tightly Coupled Scenario: This type features high interdependence among computing nodes, necessitating synchronized calculations and rapid information exchange. Typical applications are electromagnetic simulations, fluid dynamics, and car crash simulations. Such scenarios require networks optimized for extremelylow latency.
Data-Intensive Computing Scenario: Characterized by the need to handle massive amounts of data and generate significant intermediate datasets during processing. Examples include weather forecasting, gene sequencing, graphics rendering, and energy exploration. High-throughput networks are essential here, along with moderate low-latency capabilities.
RDMA over Converged Ethernet or InfiniBand over Ethernet is a network protocol that allows remote direct memory access (RDMA) over an Ethernet network. It does this by encapsulating an InfiniBand (IB) transport packet over Ethernet. In short, it can be seen as the application of RDMA technology in hyper-converged data centers, cloud, storage, and virtualization environments.
v1 is an RDMA protocol based on the Ethernet link layer (the switch needs to support PFC and other flow control technologies to ensure reliable transmission at the physical layer), allowing communication between any two hosts in the same Ethernet broadcast domain.
v2 overcomes the limitation of v1 binding to a single VLAN. v2 can be used across L2 and L3 networks by changing packet encapsulation, including IP and UDP headers.
v1 & v2 Packet format
How to Realize it?
To implement RDMA for data centers, a network card driver and network adapter that supports RoCE can be installed. All Ethernet NICs require a RoCE network adapter card. It is available in two ways: for network switches, you can choose to use switches that support PFC (Priority Flow Control) network operating system; for servers or hosts, you need to use a network card.
Understanding of InfiniBand
What is InfiniBand?
InfiniBand (abbreviated as IB), is a communication standard for high-performance computing that offers remarkable throughput and minimal latency for computer-to-computer data interconnections. It is used both as a direct or switched interconnect between servers and storage systems, as well as an interconnect between storage systems. With the exponential growth of artificial intelligence, InfiniBand has become the preferred network interconnect technology for GPU servers.
InfiniBand’s network architecture
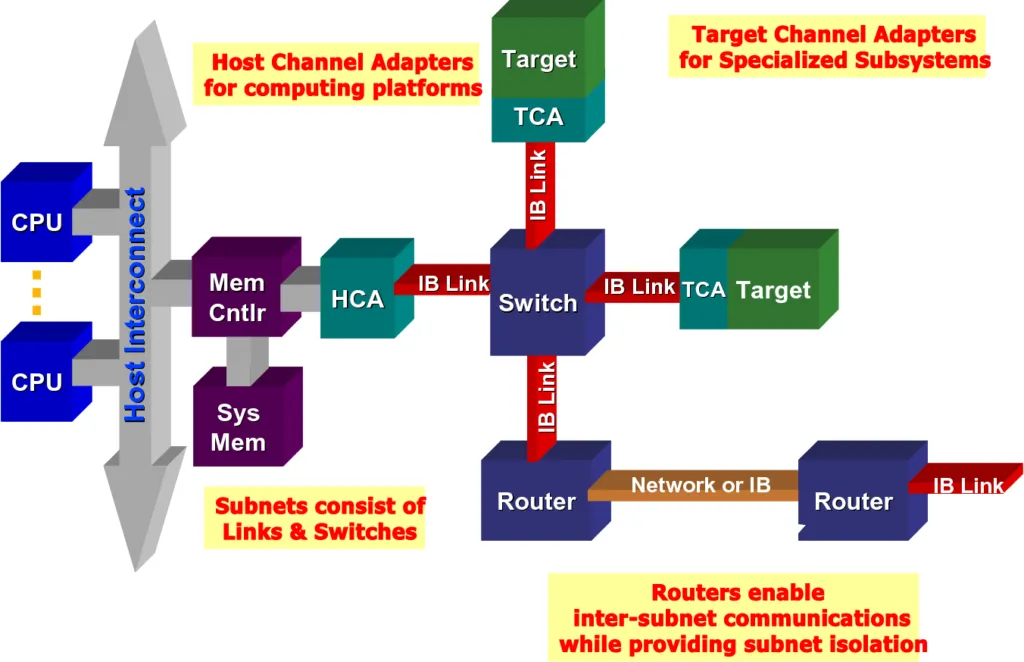
InfiniBand is a communications link for data flow between processors and I/O devices, supporting up to 64,000 addressable devices. InfiniBand Architecture (IBA) is an industry-standard specification that defines a point-to-point switching input/output framework for interconnecting servers, communications infrastructure, storage devices, and embedded systems.
InfiniBand is ubiquitous, low-latency, high-bandwidth, and low-management cost, and is ideally suited for connecting multiple data streams (clustering, communications, storage, management) in a single connection with thousands of interconnected nodes. The smallest complete IBA unit is a subnet, and multiple subnets are connected through routers to form a large IBA network.
An InfiniBand system consists of channel adapters, switches, routers, cables, and connectors. the CAs are categorized as host channel adapters (HCAs) and target channel adapters (TCAs). IBA switches are similar in principle to other standard network switches but must meet the high performance and low cost requirements of InfiniBand. The HCA is the device point at which IB end nodes, such as servers or storage devices, connect to the IB network. the TCA is a special form of channel adapter used primarily in embedded environments, such as storage devices.
The HCA is the device point where IB end nodes (such as servers or storage devices) connect to the IB network. TCA is a special form of channel adapter used primarily in embedded environments such as storage devices.
InfiniBand‘s shortcomings and limitations:
Since InfiniBand (IB) boasts numerous ultimate advantages, it is intriguing to wonder why the industry is increasingly expressing hopes for Ethernet to become the preferred technology for artificial intelligence workloads amidst the explosive development of artificial intelligence. As time goes by, it has been revealed that the industry has also discovered several fatal shortcomings of InfiniBand:
Very High Costs: The primary drawback of InfiniBand is its exorbitant price tag when compared to Ethernet. Constructing a dedicated network using InfiniBand requires a designated IB network card and switch, which generally costs five to ten times more than ordinary network equipment. Consequently, InfiniBand is only seriously considered for implementation in high-end industries such as finance and futures trading.
Elevated O&M Expenses: InfiniBand, being a dedicated network technology, cannot leverage the user’s existing IP network infrastructure and accumulated knowledge in terms of operation and maintenance. Enterprises opting for InfiniBand must hire specialized personnel to handle the specific operation and maintenance requirements. However, due to the limited market space occupied by InfiniBand (less than 1% of Ethernet), there is a severe shortage of experienced operation and maintenance personnel in the industry. Network failures may go unrepaired for extended periods of time, leading to exorbitant operational expenses (OPEX).
Vendor lock in: The presence of vendor lock-in is a major drawback of InfiniBand switches. These switches are manufactured by specific vendors and use proprietary protocols, making it difficult for them to communicate with other network devices that use IP Ethernet. This closed architecture also poses a risk to businesses that require scalable expansion in the future, as being tied to a single vendor can lead to uncontrollable risks.
Long lead time: The long lead time of InfiniBand switches is another concern. Their arrival is unpredictable, which increases project risk and hampers business expansion.
Slow upgrade: The upgrade process of the network depends on individual vendors’ product releases, preventing unified upgrades across the industry. This slowness in upgrades can hinder the overall progress of the network.
Compared to InfiniBand, RoCE provides greater versatility and better price/performance ratio. It not only allows the construction of high-performance RDMA networks but is also compatible with traditional Ethernet networks.
What makes RDMA superior to TCP/IP?
RDMA excels with its kernel bypass mechanism, which facilitates direct data exchange between applications and network cards, sidestepping TCP/IP limitations and cutting protocol stack latency down to almost 1 microsecond. Additionally, RDMA’s zero-copy memory mechanism eliminates the need to shuffle data between application memory and OS buffers. This means transmission doesn’t engage the CPU, cache, or context switches, significantly slashing processing delays in message transfer. Moreover, this transmission happens concurrently with other system operations, boosting network performance.
However, RDMA is highly sensitive to packet loss. Unlike the well-known TCP protocol that retransmits lost packets with precision—removing received messages to avoid redundancy while only resending what’s lost—the RDMA protocol retransmits all messages in a batch when a single packet is lost. Therefore, RDMA can handle full-rate transmissions flawlessly in a lossless environment, but its performance plummets sharply upon packet loss. A packet loss rate above 0.001 can drastically reduce effective network throughput, and at a rate of 0.01, it drops to zero. For optimal RDMA performance, the packet loss rate must stay below 1e-05 (one in 100,000), ideally achieving zero packet loss. This makes achieving a lossless state crucial for ROCE networks.
The most important technology on ROCE –ECN/PFC
ECN (Exploration Congress Notification) is an important means of building a lossless Ethernet that provides end-to-end flow control. Using the ECN feature, once congestion is detected, the network device marks the ECN domain at the IP head of the packet. When ECN-marked packets arrive at their intended destination, congestion notifications are fed back to the traffic sending side. The traffic sender then responds to the congestion notification by limiting the rate of the problematic network packets, thus reducing network latency and jitter of high performance computing clusters.
How ECN works ?
The sending server sends an IP message with an ECN mark.
The switch receives the message when the queue is congested, modifies the message ECN field and forwards it.
The receiving server receives the marked congestion message and processes it normally.
The receiving end generates a congestion notification and periodically sends a CNP (Congestion Notification Packets) message, requiring that the message cannot be discarded by the network.
After receiving the CNP message, the switch forwards the message normally.
The sending server receives the marked CNP message, parses it, and uses the corresponding data flow rate limit algorithm to limit the rate.
Provides Lossless Networking Using Priority Flow Control (PFC )
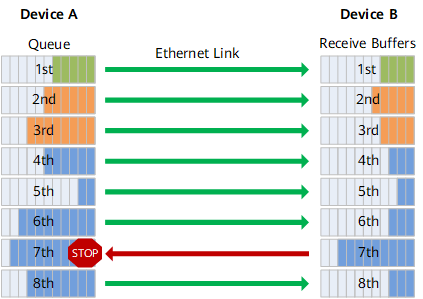
As an enhancement of the pause mechanism, Priority Flow Control (PFC) allows 8 virtual channels to be created on an Ethernet link, assigning a priority level to each virtual channel and allocate dedicated resources (such as cache, queue, etc.), allowing individual to suspend and restart any one of the virtual channels without affecting other virtual channels’ traffic transmission .This approach enables the network to create a lossless service for a single virtual link and to coexist with other traffic types on the same interface.
How does PFC work?
As shown in the figure, the sending interface of Device A is divided into 8 priority queues, and the receiving interface of Device B has 8 receiving buffers, which correspond to each other. When a receiving buffer on the receiving interface of Device B is congested, a back pressure signal “STOP” is sent to Device A, and Device A stops sending traffic in the corresponding priority queue.
It can be seen that PFC solves the conflict between the existing Ethernet Pause mechanism and link sharing. The flow control is only for one or several priority queues, rather than interrupting the traffic of the entire interface. Each queue can pause or restart traffic sending separately without affecting other queues, truly realizing multiple traffic sharing links.
Asterfusion CX-N Low Latency ROCE Switches In HPC Scenario
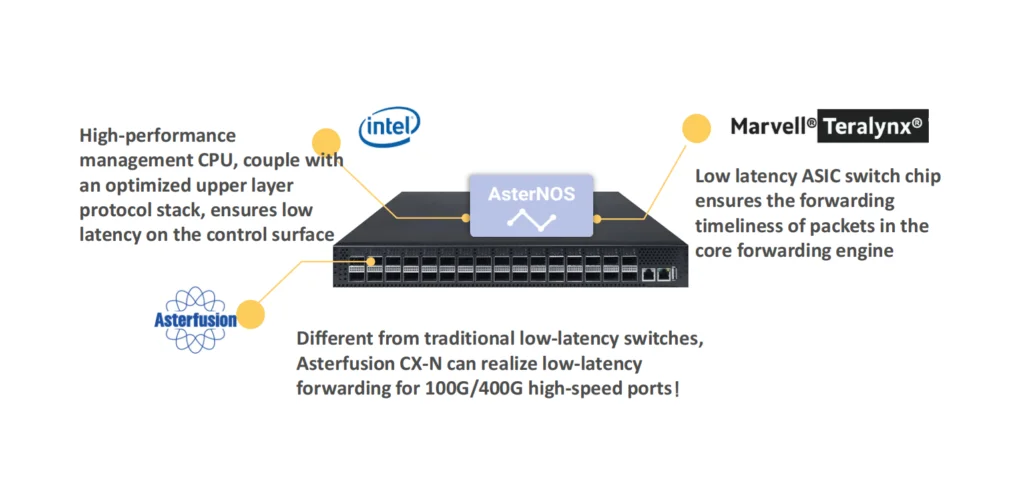
Based on the understanding of high-performance computing network requirements and RDMA technology, Asterfusion launched the CX-N series of ultra-low latency cloud switches. It uses a fully open, high-performance network hardware + transparent SONiC -based open network system (AsterNOS), to build a low latency, zero packet loss, high-performance Ethernet network for HPC scenarios, which not bound by any vendor.
Extremely cost-effective, CX-N switches have port to port minimum 400ns forwarding delay,the forwarding delay is the same at full rate (10G~400G);
Supports RoCEv2 to reduce the delay of transmission protocol;
Support PFC, ECN, DCTCP,etc. to deliver low-latency, zero packet loss, non-blocking Ethernet;
Test Data Of Asterfusion Ultra Low Latency Switch Vs. InfiniBand Switch On HPC Scenorio
01 Lab Test
This test was conducted on the network built by CX-N ultra-low latency cloud switch (CX-N for short) and Mellanox MSB7800 (IB for short) switch.
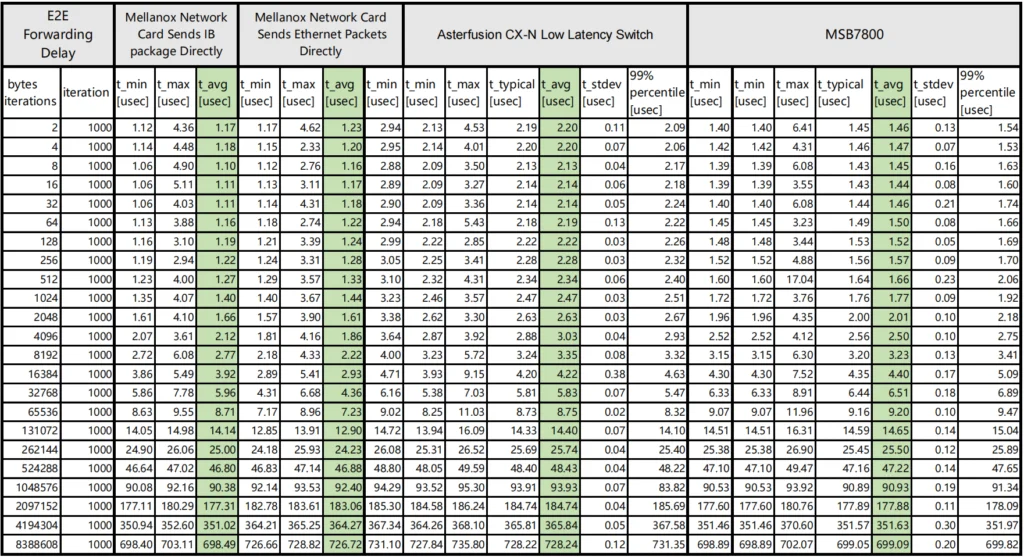
Test 1: E2E forwarding
Test E2E (End to End) forwarding latency and bandwidth of the two switches under the same topology.
This scheme uses Mellanox IB packet delivery tool to send packets, and the test process traverses 2~8388608 bytes.
The CX-N switch has a bandwidth of 92.25Gb/s and a single delay of 480ns.
The bandwidth of the IB switch is 96.58Gb/s, and the delay of a single unit is 150ns.
In addition, the CX-N ‘s delay fluctuation of traversing all bytes is smaller, and the test data is stable at about 0.1us.
Comparing Asterfusion CX-N low latency switch and Mellanox IB , the CX-N is more cost-effective.
Table 1: Comparison of AsterfuionCX-N vs IB forwarding delay data
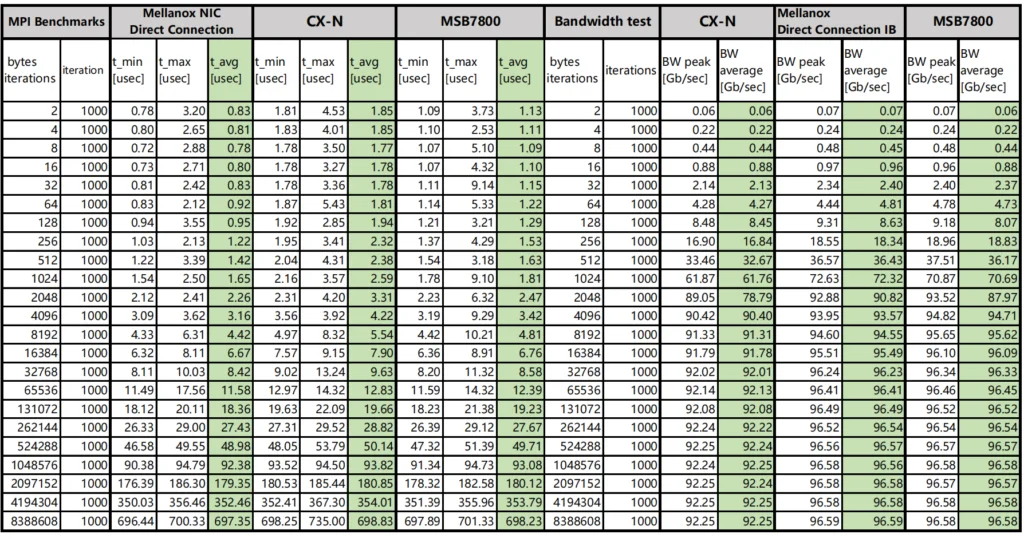
Test 2 (MPI benchmark)
MPI benchmarks are commonly used to evaluate high performance computing ‘s performance.
OSU Micro-Benchmarks are used to evaluate the performance of Asterfusion CX-N and IB switches.
The CX-N switch has a bandwidth of 92.63Gb/s and a single delay of 480ns.
The bandwidth of the IB switch is 96.84Gb/s, and the delay of a single unit is 150ns.
Table 2: Comparison of CX-N vs IB MPI test data
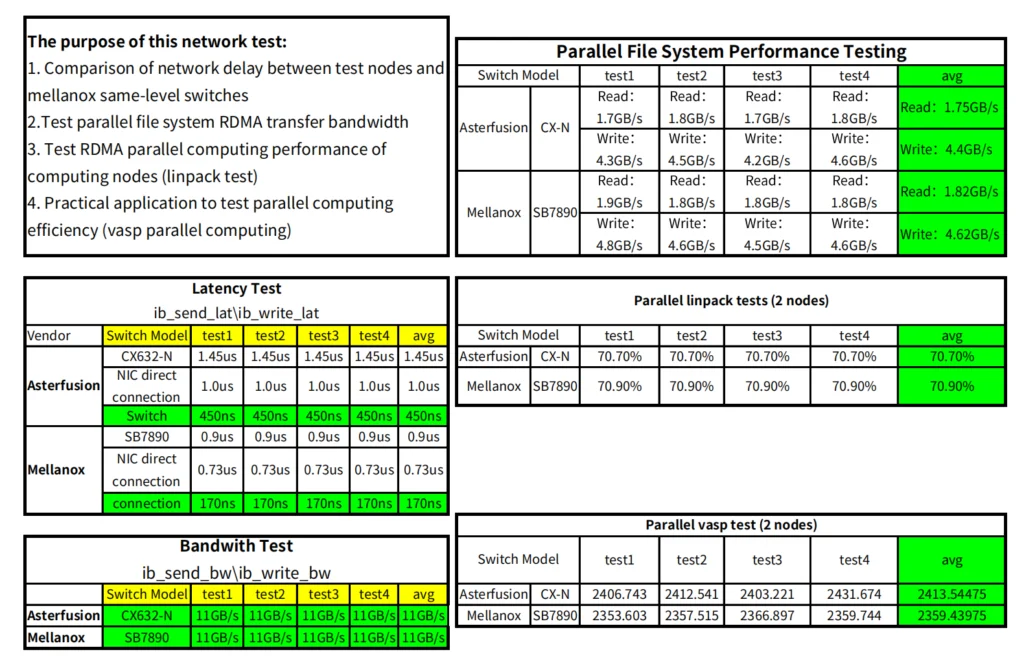
Test 3: HPC Applications
Run the same tasks in each HPC application and compare the speed of the CX-N and IB switches. Conclusion: The operating speed of CX-N switches is only about 3% lower than that of IB switches.
Table 3: Comparison of CX-N vs IB HPC application test
02 Comparison of customer field test data
It is basically consistent with the results obtained in the lab, and even better.
Asterfusion CX-N low latency switches utilize ROCE to deliver the performance of IB switches at a significantly lower price, making it an affordable for HPC scenarios.
When enterprise users have a limited budget, but at the same time have a high demand for latency in HPC scenarios, which can choose Asterfusion Teralynx based CX-N low latency switches as a chioce. It offers a truly low-latency, zero-packet-loss, high-performance, and cost-effective network for high-performance computing clusters.
For more information about Asterfusion CX-N low latency ROCE switch, please contact bd@cloudswit.ch
Imagine a world where artificial intelligence doesn’t just analyze data, but creates it. Where AI systems generate stunning works of art, craft compelling stories, and even compose music. This isn’t the stuff of science fiction anymore-it’s the reality of generative AI. And it’s transforming the way we think about data centers. The rise of OpenAI’s ChatGPT and Google’s Bard is just the beginning. The generative AI market is projected to skyrocket to a staggering $126.5 billion by 2031, growing at a mind-boggling 32% per year. At the heart of this revolution are the data centers that power these AI powerhouses. But they’re not your average data centers. They’re specialized AI data center networks, designed from the ground up to meet the unique demands of generative AI. What is AI Data Center Network? AI Data Center Network refers to a data center network fabric that supports artificial intelligence (AI). It meets the stringent network scalability, performance, and low latency requi...
Regardless of whether it's a conventional data center or a modern cloud-based data center, the universal necessity is high availability, and a prevalent issue is the potential single point of failure within the network. In traditional physical networking, to establish highly dependable connections between various devices, LAG (Link Aggregation) technology was developed to ensure high availability of links between servers and switches or even between multiple switches. However, LAG technology possesses its own flaws and is unable to eliminate the risk of equipment failure entirely. Thus, a more advanced technology is required to broaden the original one-to-one connection between devices into a one-to-many connection while ensuring multi-device redundancy and multi-link redundancy. It must also guarantee that devices are able to interconnect with optimal robustness. Introducing MC-LAG, an enhancement of the traditional LAG technology. To accurately comprehend the workings of MC-LAG, ...
Ceph is a very popular and widely used SDS ( Software Defined Storage ) solution, which can provide object, block and file-level storage at the same time. This article will show you how to use Asterfusion CX-N series ultra-low-latency switches to form a network to carry Ceph storage clusters and use Ceph as the storage backend to integrate with Openstack. Before the popularization of cloud technology, common storage solutions in the IT industry were DAS, SAN, and NAS. Currently, the three traditional storage solutions have some problems in terms of price, performance, scalability, deployment, operation and maintenance in their respective application scenarios. So, there is no one-size-fits-all solution on storage. In actual production environments, we often need to make trade-offs based on data size, performance requirements, budget, and application scenarios. The emergence of Ceph is a compromise solution to the above problems. What is Ceph ? Ceph is a very popular o...





评论
发表评论